
The challenge



For this Hackathon, the challenge is to use available data related to biodiversity (stressors and habitats) to support the implementation of actionable biodiversity risk maps.
Three study areas are the object of the hackathon:
- The North Sea
- The Waddenzee
- The Veluwe
Your challenge will be to use the data provided for these areas to:
- improve the usability of the data using AI
- create a multistressor risk map for biodiversity
- create a tool useful for the challenge commissioner to access this map for understanding the impacts of multiple stressors on biodiversity in one of the case study areas.
Extra points will be awarded for teams being able to cover two or more of these missions.

Missions
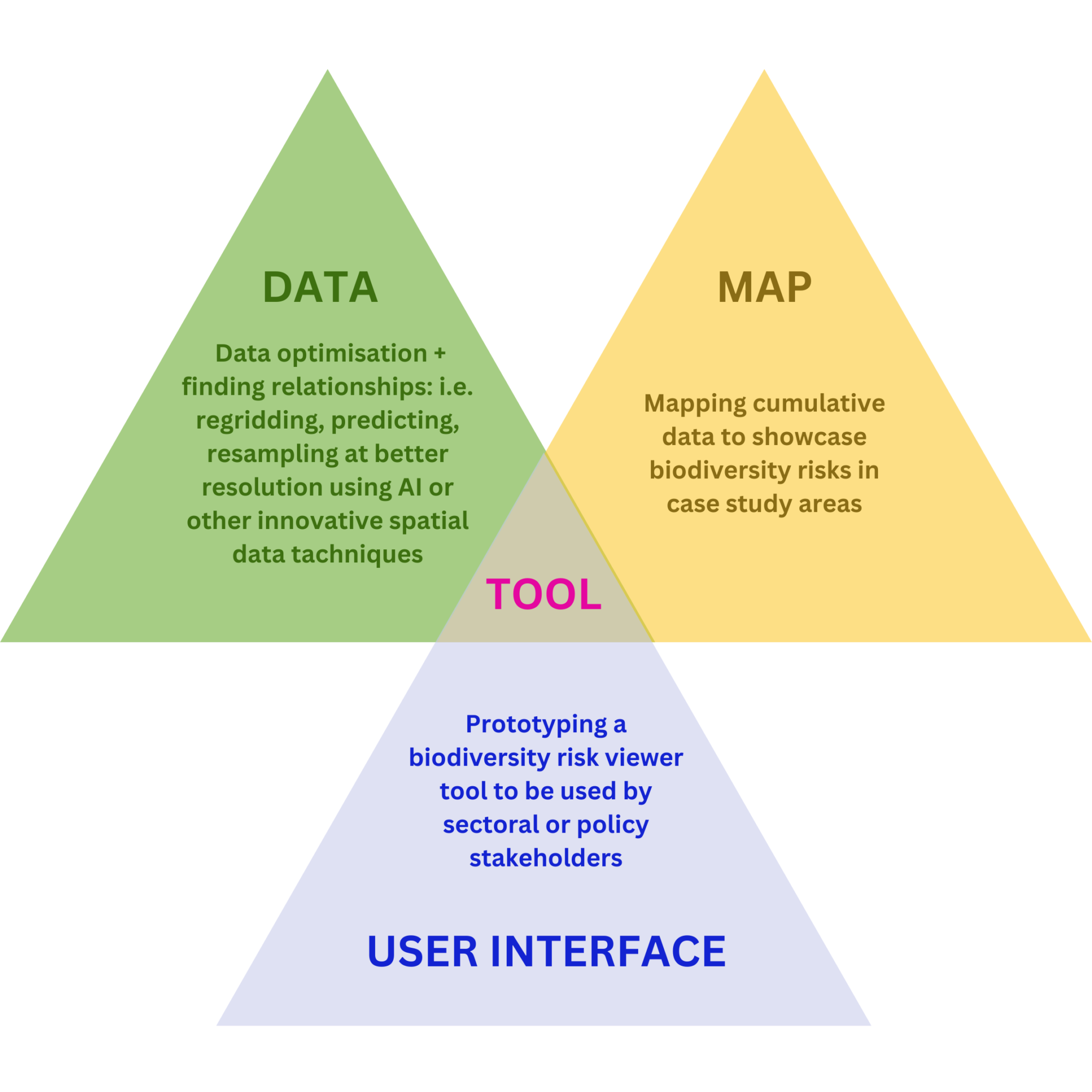
The hackathon participants can formulate challenges covering one or more of the pillars guided by the elements that fall under these pillars.
Possible elements of the challenges
1) Data
- Find more data for relevant biodiversity components and potential stressors[1] from the structured sources (structured databases) or unstructured sources (literature, news, social media through text mining).
- Improve data quality by addressing issues such as missing values, outliers, and inconsistencies.
- Enhance data accessibility and interoperability through standardization and integration efforts.
- Harmonizing data with different spatial and temporal resolutions or covering different areas or periods.
2) Map
- Interpolation of spatial data to provide high(er)-resolution maps. For example, data from monitoring programs using environmental information.
- Extrapolating spatial distributions covering only part of the case study area so that it covers the whole area.
- Extrapolating current spatial distributions into the future. For example, to address climate change
3) User interface
- Present multi-faceted information (e.g. human activities impacting biodiversity components through pressures) to decision-makers or stakeholders.
- Applied as part of Strategic Impact Assessment (SIA), also known as Strategic Environmental Assessment (SEA)[2].
- Interactive presentation of spatial data. For example a drill-down showing the main stressors per spatial datapoint.
- Allowing stakeholders to create spatial distributions that can be incorporated into the assessment
The tool(s):
- Can be a machine learning model that can efficiently combine information into spatial datasets.
- Should explicitly take into account the spatial and temporal dependency in the data.
- Can be either parametric (e.g., classical auto-regressive models) or non-parametric (e.g., spatial-temporal deep learning model such as convolutional LSTM)
- Should be tested using sound cross-validation techniques to ensure its reliability and generalizability.
- Can be an ensemble modeling approaches to leverage the strengths of multiple models and improve prediction accuracy.
- May involve transfer learning approaches to leverage pre-trained models and adapt them to the specific biodiversity context.
[1] Lists of biodiversity components and potential stressors are provided per case study
[2] Assessment of the wider environmental, social and economic impacts of alternative proposals at the beginning of a project.

